Altersstrukturen und Clusteranalyse europäischer Fußballnationalmannschaften: Eine k-means Klassifikation
Abstract
Dieser Artikel untersucht die Altersstrukturen europäischer Fußballnationalmannschaften mittels einer k-means Clusteranalyse. Basierend auf Daten von 24 Nationalteams, die verschiedene statistische Kennzahlen wie Median, Mittelwert, Quartile und Standardabweichung des Alters der Spieler umfassen, wurden die Teams in unterschiedliche Cluster eingeteilt. Die Analyse ergab drei Hauptcluster: Teams mit jüngeren Spielern, Teams mit hoher Altersdiversität und Teams mit älteren Spielern. Diese Klassifizierung liefert wertvolle Einblicke in die Teamzusammensetzung und unterstützt die strategische Entscheidungsfindung im Profifußball. Der Artikel beschreibt die angewandte Methodik, die Ergebnisse der Clusteranalyse und deren praktische Implikationen für die Kaderplanung.
1 Einleitung
Die Altersverteilung in Fußballteams ist ein entscheidender Faktor, der die Dynamik, Erfahrung und Leistungsfähigkeit eines Teams beeinflusst. Während junge Spieler oft durch ihre körperliche Fitness und schnelle Anpassungsfähigkeit glänzen, bringen erfahrene Spieler strategische Tiefe und Stabilität ins Team. Diese Studie zielt darauf ab, die Altersstrukturen verschiedener europäischer Nationalmannschaften zu untersuchen und zu klassifizieren.
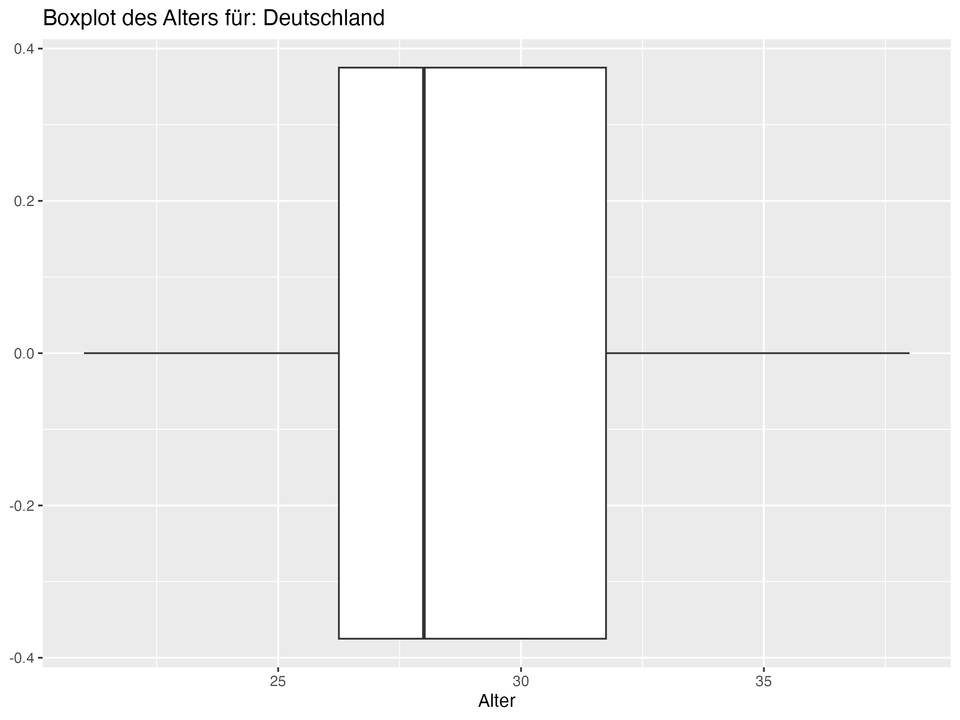
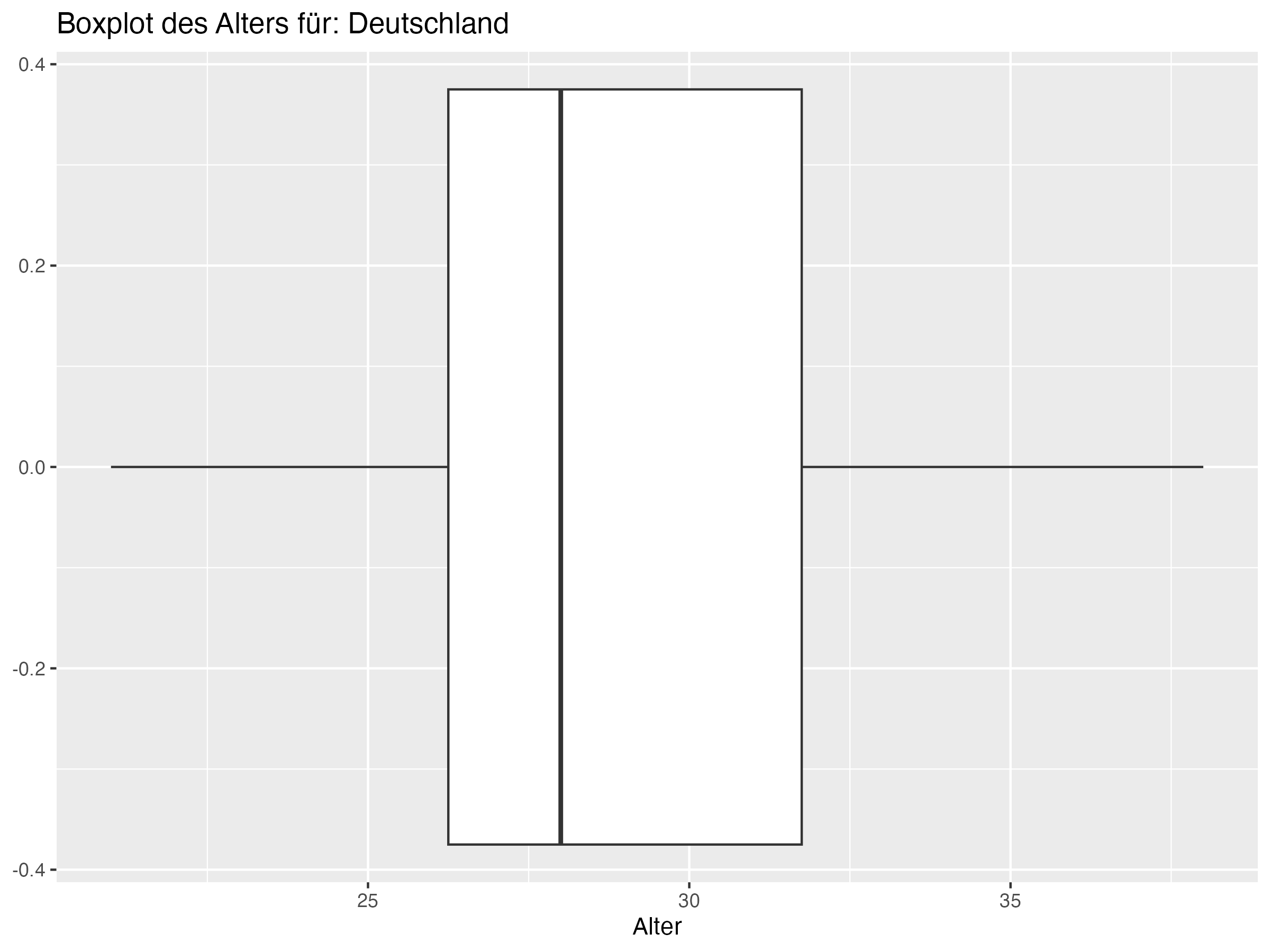
Die bevorstehende Europameisterschaft 2024 bietet einen idealen Kontext für diese Untersuchung, da sie bemerkenswerte Unterschiede in den Altersprofilen der teilnehmenden Teams zeigt. Besonders hervorzuheben ist die deutsche Fußball-Nationalmannschaft, die mit einem Durchschnittsalter von 28,5 Jahren als die älteste Mannschaft des Turniers gilt. Dies wird noch verstärkt durch den ältesten Profi im DFB-Aufgebot, Torhüter Manuel Neuer, der 38 Jahre alt ist. Im Gegensatz dazu stellen Tschechien und die Türkei die jüngsten Mannschaften.
Durch die Anwendung der k-means Clusteranalyse können wir Teams mit ähnlichen Altersprofilen identifizieren und analysieren. Die Ergebnisse dieser Studie bieten wertvolle Einblicke für Trainer, Manager und Analysten, die die Zusammensetzung ihrer Teams optimieren möchten.
Hauptforschungsfragen:
- Wie variieren die Altersstrukturen der europäischen Nationalmannschaften bei der EM 2024?
- Welche Muster und Cluster können in den Altersverteilungen der teilnehmenden Mannschaften identifiziert werden?
Nebenforschungsfragen:
- Inwiefern beeinflusst das Durchschnittsalter eines Teams seine Klassifizierung in verschiedene Cluster?
- Welche Teams zeichnen sich durch eine besonders hohe oder niedrige Altersdiversität aus?
2 Methode
Datensatz und Variablen
Die Daten für diese Studie wurden von 24 europäischen Nationalmannschaften gesammelt und beinhalten detaillierte Informationen zur Altersverteilung der Spieler. Für jede Mannschaft wurden die folgenden statistischen Kennzahlen berechnet:
- Minimum: Das Mindestalter der Spieler im Team, welches das jüngste Mitglied des Teams darstellt.
- 1. Quartil (Q1): Der Wert, unter dem 25% der beobachteten Altersdaten liegen. Es ist ein Maß für die unteren 25% der Altersverteilung.
- Median: Der Wert, unter dem 50% der beobachteten Altersdaten liegen. Der Median teilt die Altersdaten in zwei gleiche Hälften und ist ein robuster Indikator für das mittlere Alter.
- Mittelwert (Mean): Das arithmetische Mittel des Alters der Spieler, berechnet als Summe aller Alterswerte geteilt durch die Anzahl der Spieler.
- 3. Quartil (Q3): Der Wert, unter dem 75% der beobachteten Altersdaten liegen. Es ist ein Maß für die oberen 25% der Altersverteilung.
- Maximum: Das Höchstalter der Spieler im Team, welches das älteste Mitglied des Teams darstellt.
- Standardabweichung (SD): Ein Maß für die Streuung der Altersdaten um den Mittelwert, welches die durchschnittliche Abweichung der Alterswerte vom Mittelwert angibt.
- Spannweite (Range): Der Unterschied zwischen dem Maximum und dem Minimum der Altersverteilung, welcher die gesamte Bandbreite der Altersdaten im Team darstellt.
- Differenz zwischen Mittelwert und Median (Diff): Diese Kennzahl gibt Aufschluss darüber, ob die Altersverteilung symmetrisch ist (wenn Diff nahe 0 liegt) oder asymmetrisch ist (wenn Diff deutlich von 0 abweicht).
Datenvorbereitung
Die gesammelten Daten wurden in einem DataFrame gespeichert und einer Standardisierung unterzogen. Die Standardisierung der Daten war notwendig, um die Unterschiede in den Skalen der Variablen auszugleichen. Standardisierung bedeutet, dass die Werte jeder Variable so umgewandelt wurden, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben. Diese Transformation ist besonders wichtig für die k-means Clusteranalyse, da diese Methode empfindlich auf die Skalierung der Daten reagiert. Ohne Standardisierung könnten Variablen mit größeren numerischen Werten die Bildung der Cluster dominieren und die Ergebnisse verfälschen.
Clusteranalyse
Die k-means Clusteranalyse wurde angewendet, um Gruppen von Teams mit ähnlichen Altersprofilen zu identifizieren. K-means ist eine unüberwachte Lernmethode, die die Daten in kk Cluster unterteilt, wobei jedes Team zu dem Cluster gehört, dessen Mittelwert (Zentroid) am nächsten liegt. Der Algorithmus minimiert die Summe der quadratischen Abstände zwischen den Datenpunkten und den Zentroiden ihrer jeweiligen Cluster.
Die optimale Anzahl der Cluster wurde durch die Elbogenmethode bestimmt. Diese Methode beinhaltet die Berechnung des totalen Abstands innerhalb der Cluster (Total Within-Cluster Sum of Squares, WCSS) für eine Reihe von Clusterzahlen und die Auswahl der Anzahl, bei der eine deutliche "Knie"-Biegung (Elbow) in der WCSS-Kurve auftritt. Diese Biegung deutet darauf hin, dass die Hinzufügung weiterer Cluster die WCSS nur noch geringfügig reduziert.
Nach der Bestimmung der optimalen Clusteranzahl wurde der k-means Algorithmus angewendet, um die Teams entsprechend zu klassifizieren. Jedes Team wurde dabei einem Cluster zugewiesen, dessen Altersprofil es am besten repräsentiert.
Software und Tools
Die Datenanalyse und Visualisierung wurden mit der Programmiersprache R und den folgenden Paketen durchgeführt:
- dplyr: Ein Paket für die Datenmanipulation, das effiziente Funktionen zur Filterung, Transformation und Aggregation von Daten bereitstellt.
- ggplot2: Ein Paket zur Erstellung von Grafiken und Datenvisualisierungen auf Basis der Grammatik der Grafiken.
- cluster: Ein Paket, das Funktionen für Clusteranalysen bereitstellt, einschließlich der k-means Methode.
- factoextra: Ein Paket, das Tools zur Visualisierung und Interpretation von multivariaten Datenanalysen, einschließlich der k-means Clusteranalyse, bietet.
- DT: Ein Paket zur Erstellung von interaktiven HTML-Tabellen, das auf der JavaScript-Bibliothek DataTables basiert.
Die Ergebnisse der Clusteranalyse wurden visualisiert und in einer interaktiven HTML-Tabelle dargestellt, um eine einfache Interpretation und Weiterverarbeitung zu ermöglichen. Diese interaktive Tabelle erlaubt es, die Daten nach verschiedenen Kriterien zu sortieren und zu filtern, was die Analyse und Präsentation der Ergebnisse unterstützt.
3 Ergebnisse
Clusteridentifikation
Um die Hauptforschungsfrage zu beantworten, wie die Altersstrukturen der europäischen Nationalmannschaften bei der EM 2024 variieren, und die Nebenforschungsfragen zu untersuchen, wurden die Altersdaten der Spieler mittels k-means Clusteranalyse untersucht. Die Elbogenmethode wurde angewendet, um die optimale Anzahl der Cluster zu bestimmen. Diese Methode identifiziert den Punkt, an dem die Reduktion des totalen Abstands innerhalb der Cluster (Total Within-Cluster Sum of Squares, WCSS) abflacht, was darauf hinweist, dass zusätzliche Cluster keine signifikante Verbesserung der Modellgüte bringen.
Das Ergebnis der Elbogenmethode deutete auf drei optimale Cluster hin. Diese Cluster repräsentieren Gruppen von Teams mit unterschiedlichen Altersprofilen:
- Cluster 1: Teams mit jüngeren Spielern und geringerer Altersdiversität.
- Cluster 2: Teams mit hoher Altersdiversität und höheren Maximalaltern.
- Cluster 3: Teams mit älteren Spielern und moderater Altersdiversität.
Die Identifikation dieser drei Cluster ermöglicht es, die Altersstrukturen der Teams zu kategorisieren und deren spezifische Merkmale detaillierter zu analysieren.
Charakterisierung der Cluster
Um die charakteristischen Merkmale der Cluster zu verstehen und die Nebenforschungsfragen zu beantworten, wurden die Clusterzentren analysiert. Diese Analyse bietet Einblicke in die durchschnittlichen Eigenschaften der Teams innerhalb jedes Clusters:
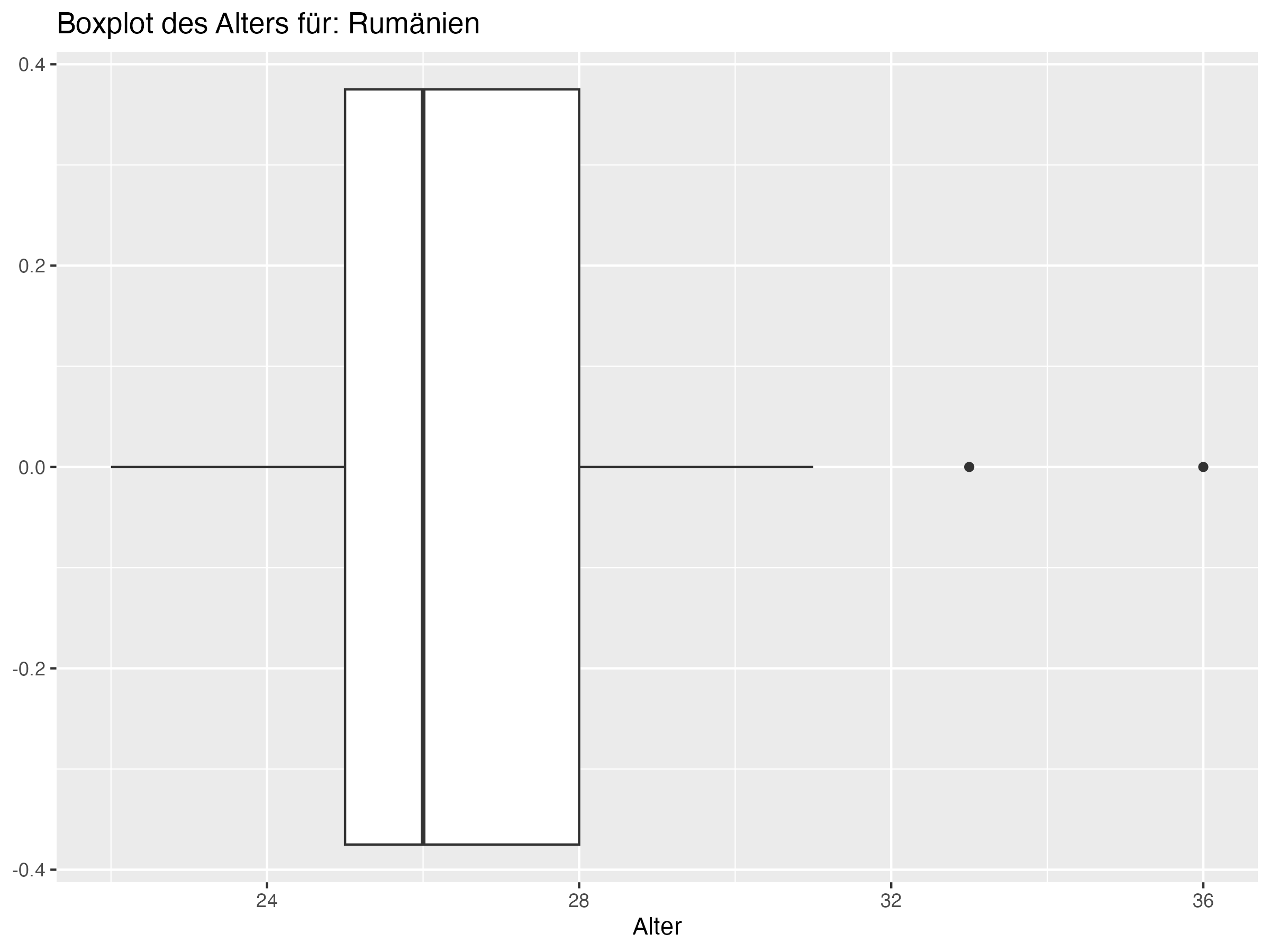
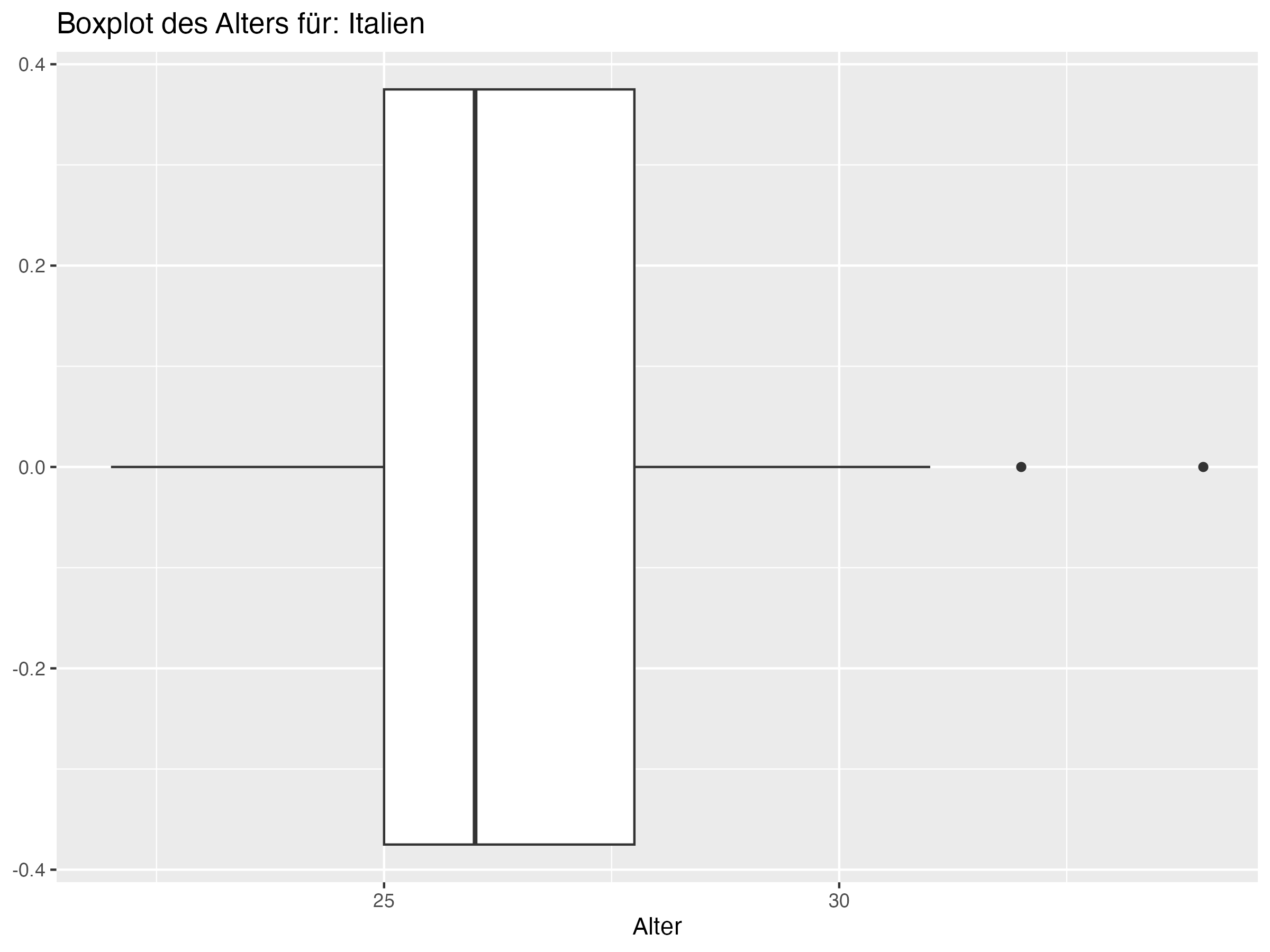
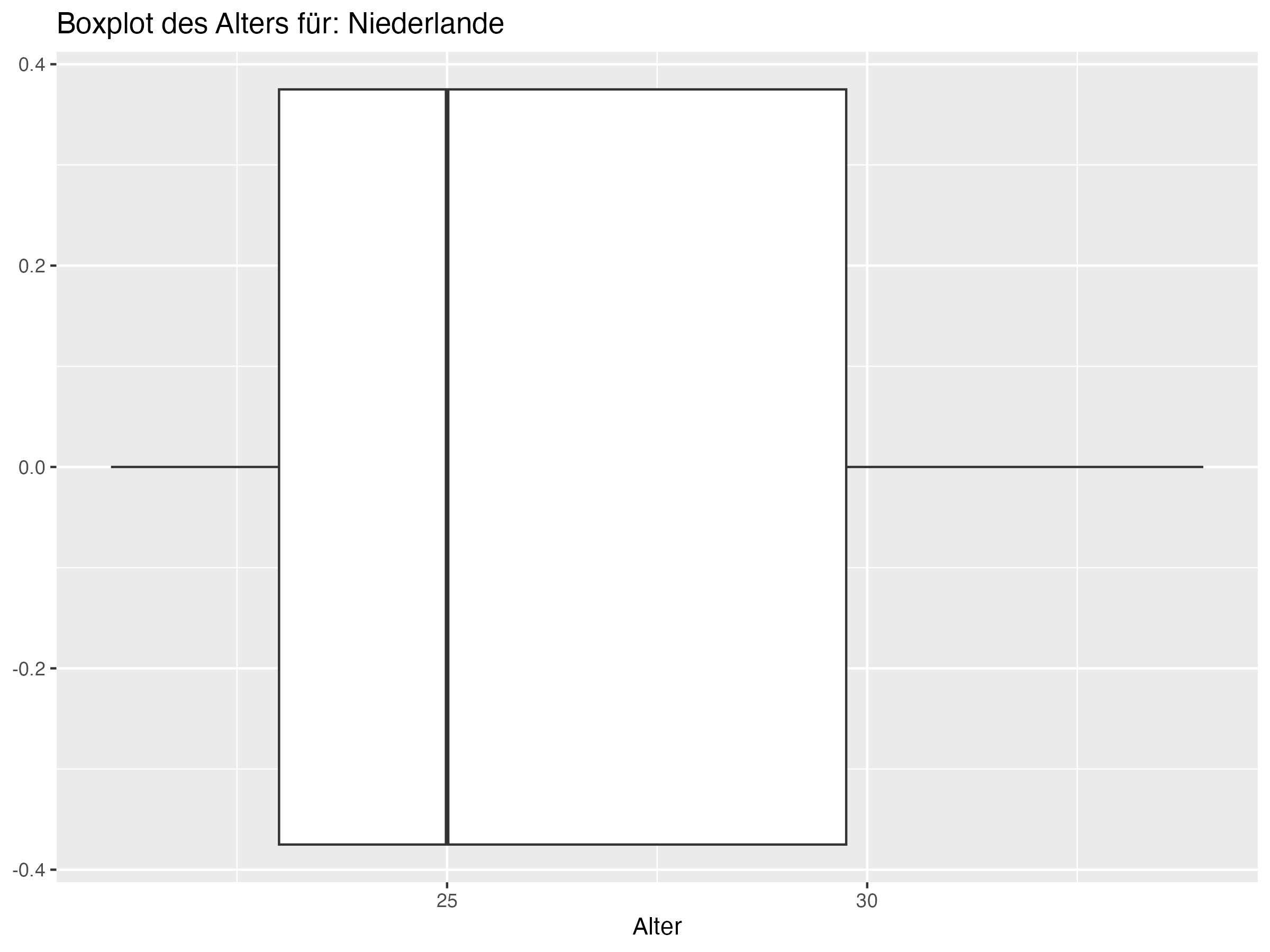
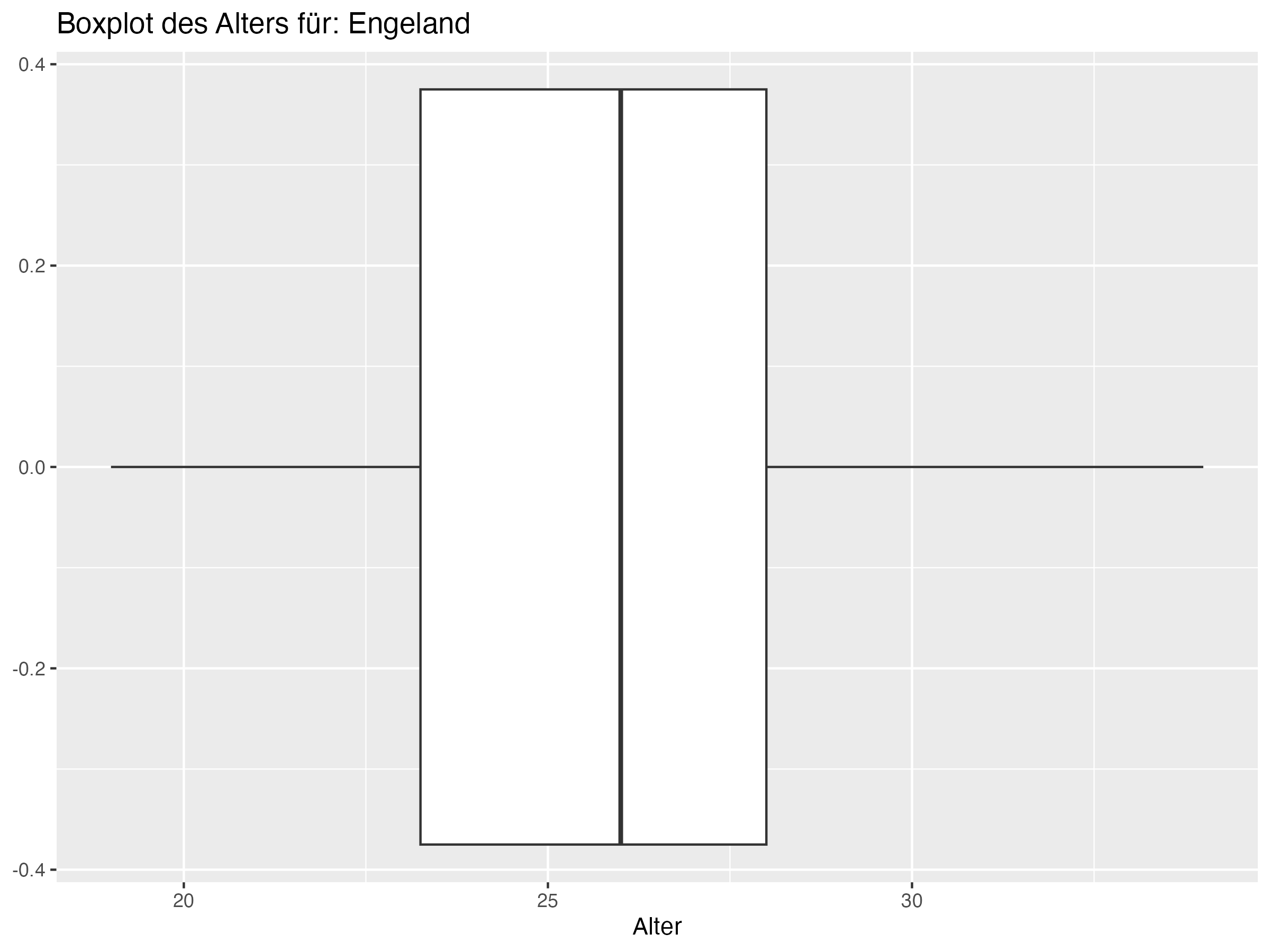
- Cluster 1: Dieser Cluster umfasst Teams wie England, Niederlande und Italien. Diese Teams zeichnen sich durch ein jüngeres Durchschnittsalter aus, wie durch den niedrigeren Median und Mittelwert des Alters ersichtlich. Die Standardabweichung und Spannweite sind ebenfalls relativ gering, was auf eine geringere Altersdiversität innerhalb der Teams hindeutet.
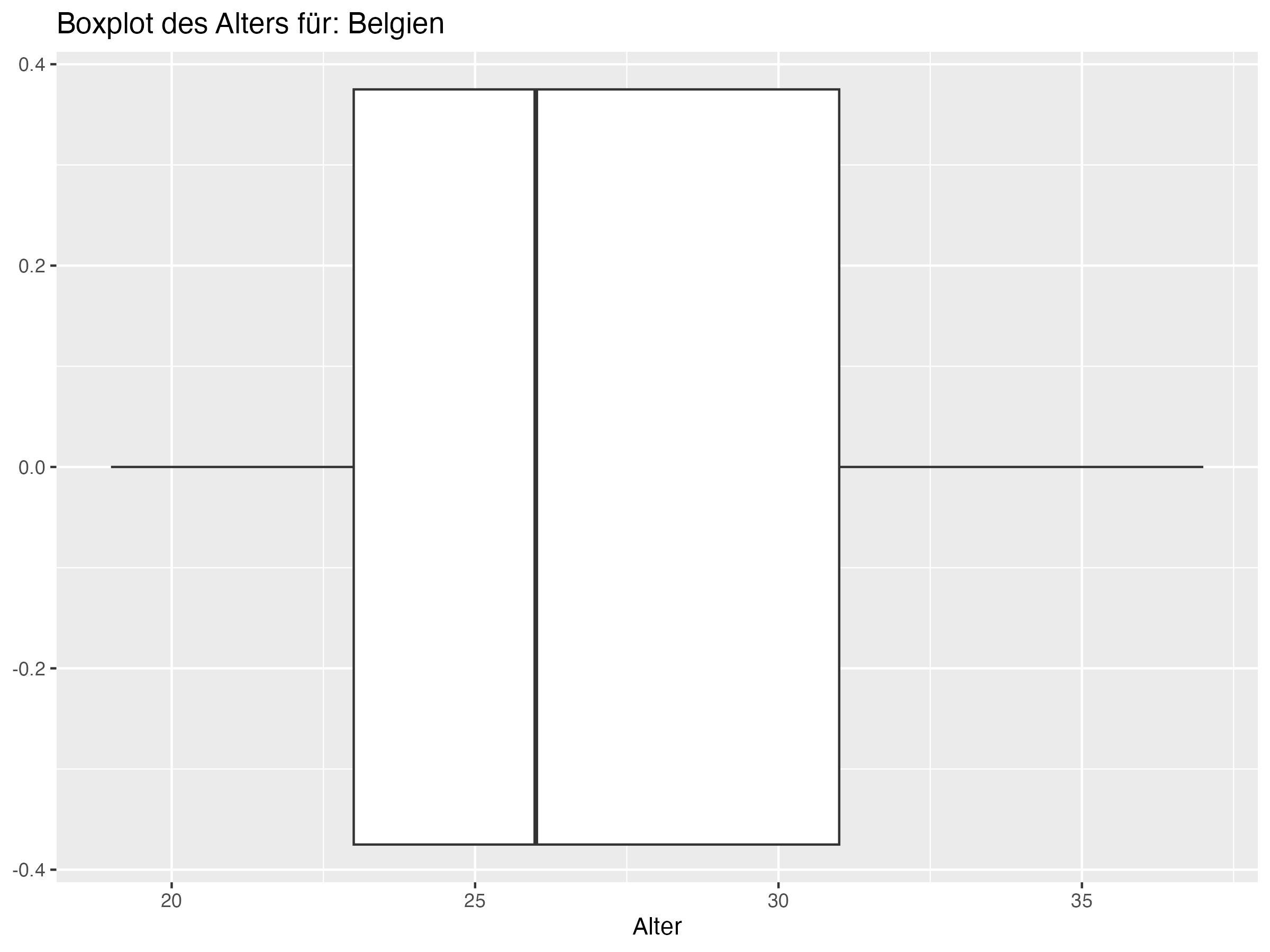
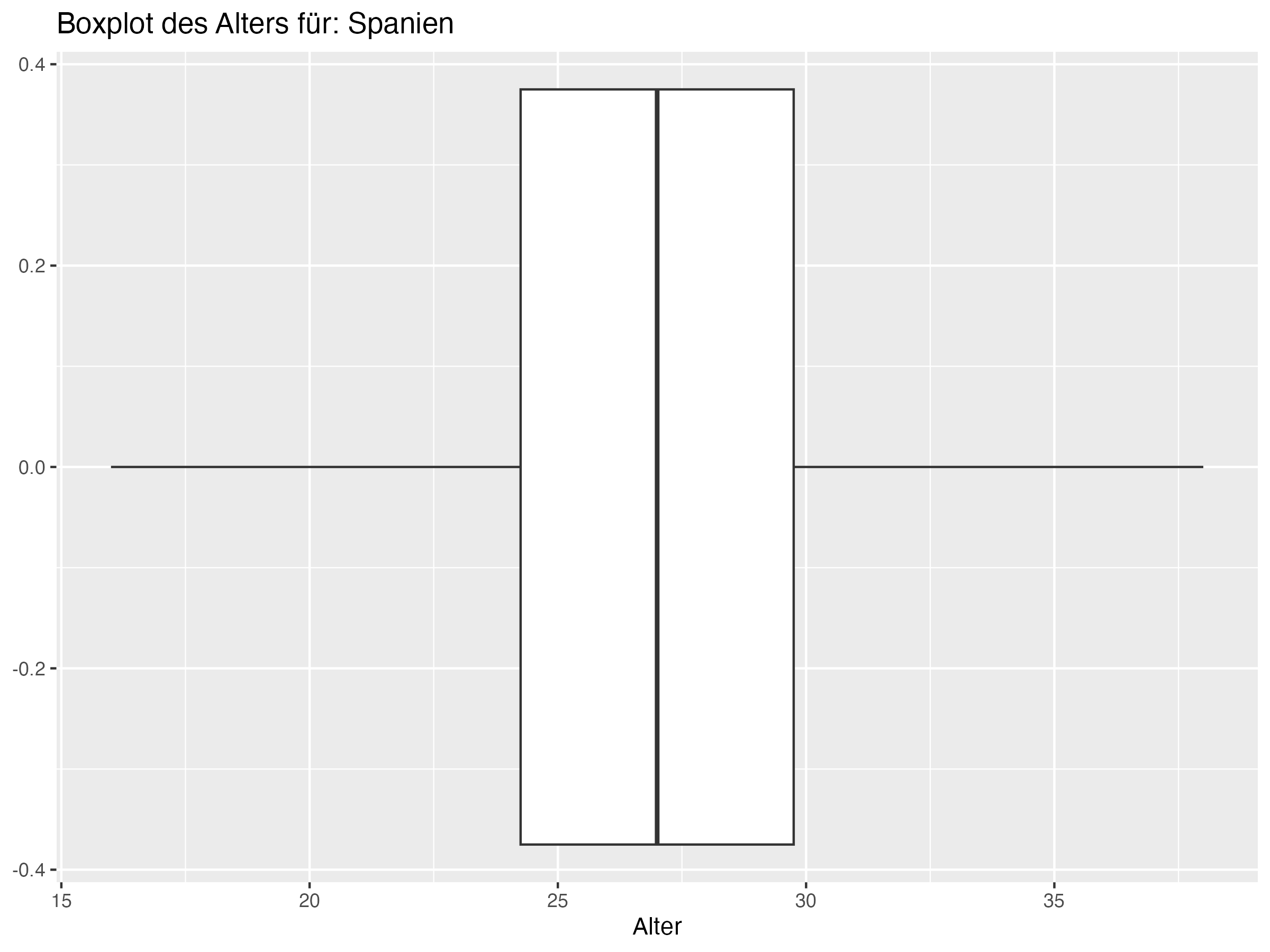
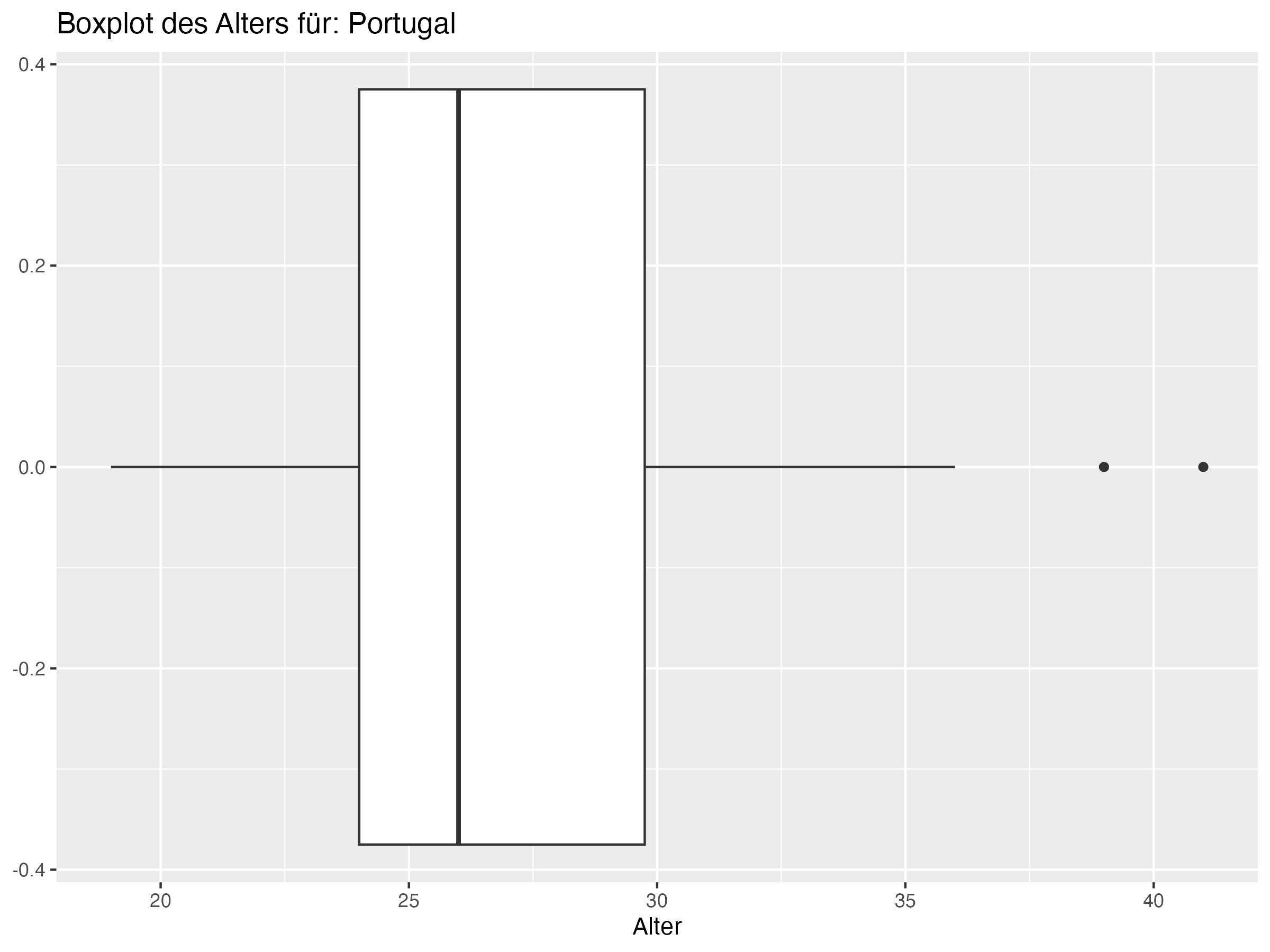
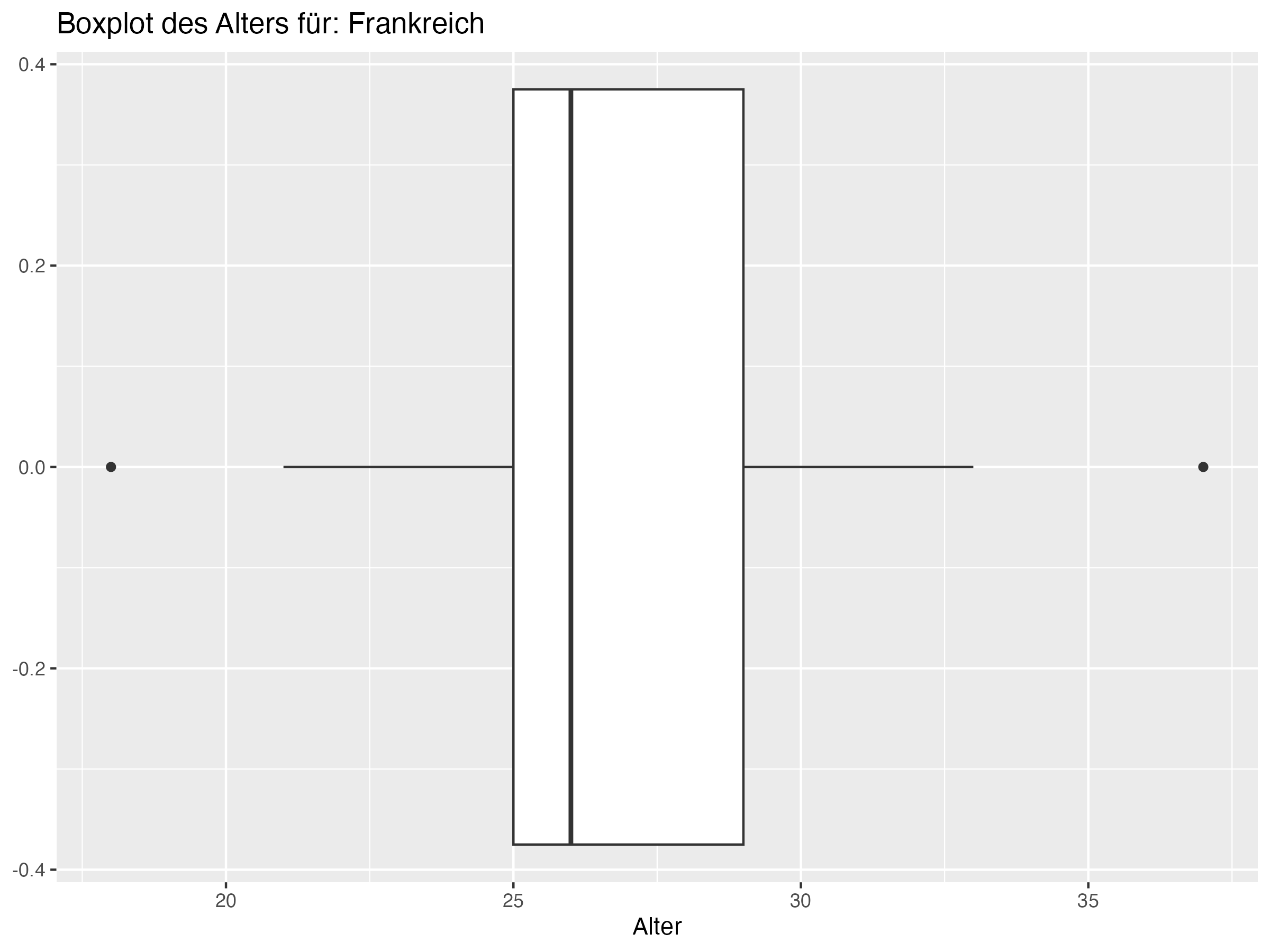
- Cluster 2: In diesem Cluster befinden sich Teams wie Frankreich, Portugal und Spanien. Diese Teams zeigen eine große Altersdiversität, wie durch eine hohe Standardabweichung und Spannweite belegt wird. Die Maximalalter in diesen Teams sind höher als in den anderen Clustern, was auf das Vorhandensein sehr erfahrener, älterer Spieler hinweist.
- Cluster 3: Dieser Cluster umfasst Teams wie Deutschland, Dänemark und Kroatien. Die Teams in diesem Cluster haben tendenziell ältere Spieler, was durch höhere Median- und Mittelwerte des Alters bestätigt wird. Die Altersdiversität ist moderat, was durch mittlere Werte der Standardabweichung und Spannweite gezeigt wird.
Die detaillierte Charakterisierung der Cluster ermöglicht es, die Altersprofile der Teams besser zu verstehen und deren strategische Zusammensetzung zu analysieren.
Visualisierung der Cluster
Um die Ergebnisse der Clusteranalyse zu visualisieren und die Verteilung der Teams in den verschiedenen Clustern zu verdeutlichen, wurde die fviz_cluster Funktion aus dem factoextra-Paket verwendet. Diese Visualisierung zeigt die Clusterzentren und die Verteilung der Teams innerhalb der Cluster, wobei die Namen der Länder in der Grafik angezeigt werden. Dies erleichtert die Interpretation der Ergebnisse und ermöglicht es, die spezifischen Altersprofile der Teams zu identifizieren.
Die Visualisierung verdeutlicht die Altersprofile der Teams und zeigt klar die Zugehörigkeit der einzelnen Teams zu den jeweiligen Clustern. Diese grafische Darstellung hilft, die Unterschiede und Gemeinsamkeiten zwischen den Teams besser zu verstehen
Die folgende Abbildung zeigt die Clusterverteilung der Teams:
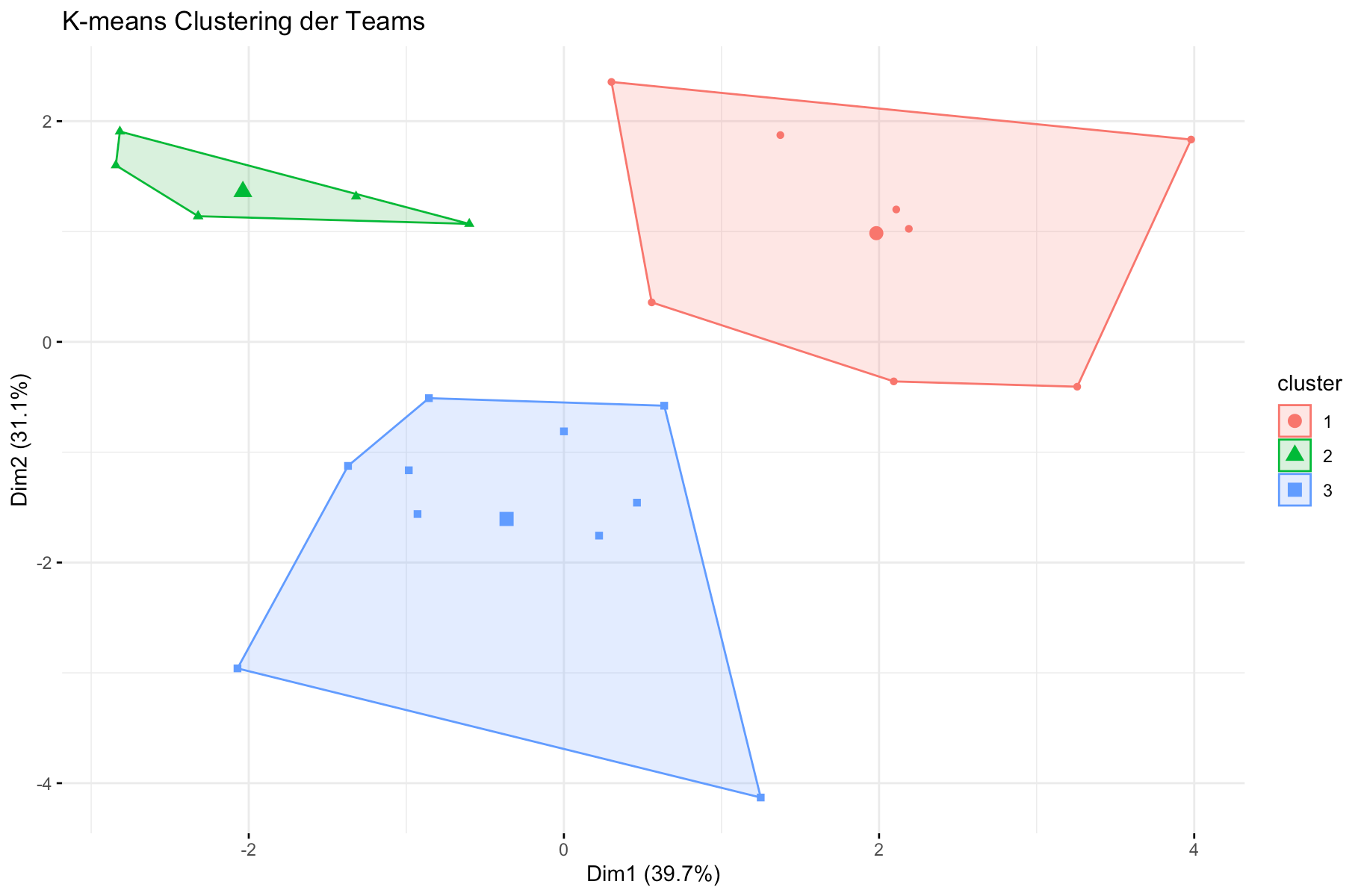
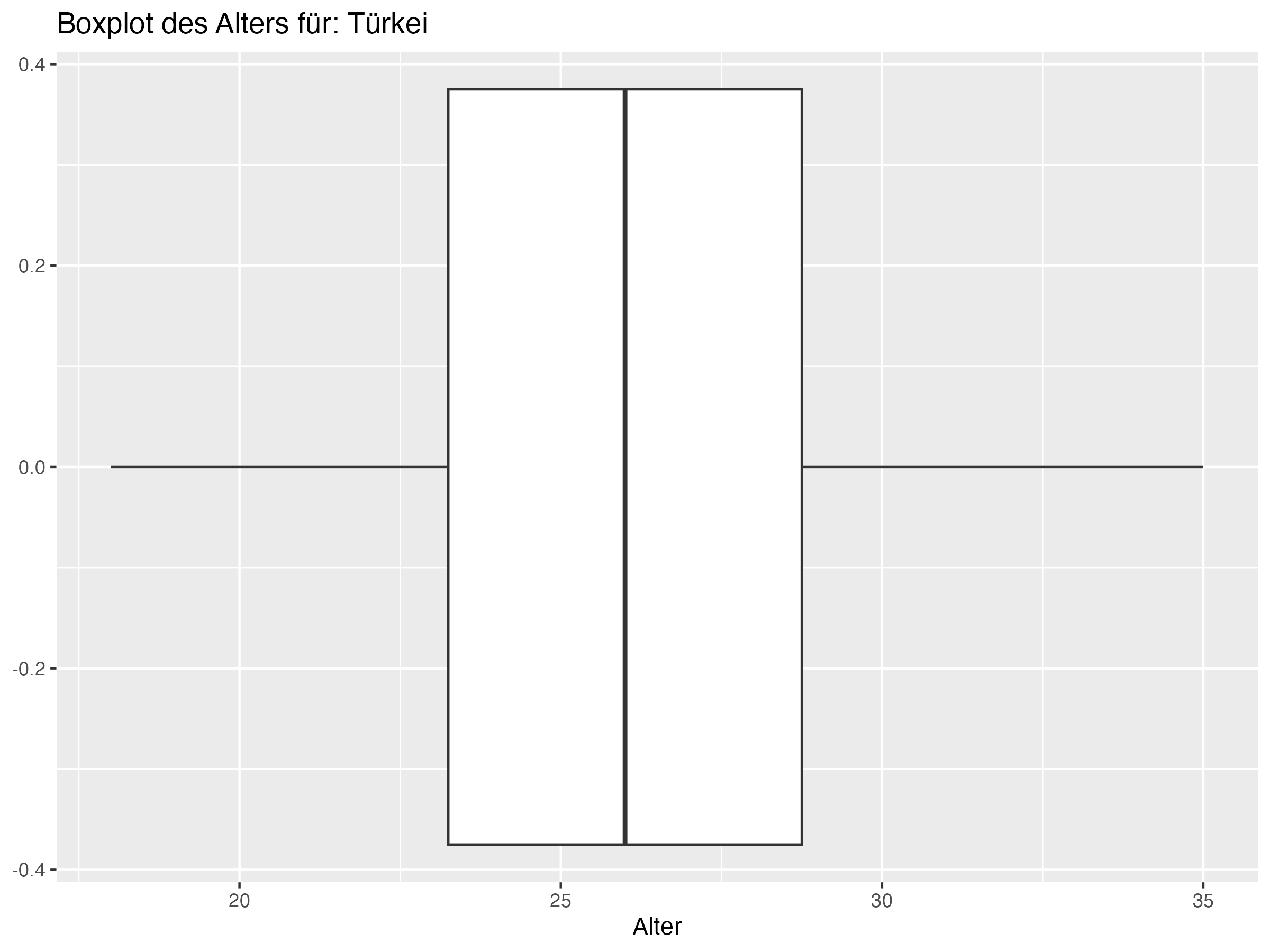
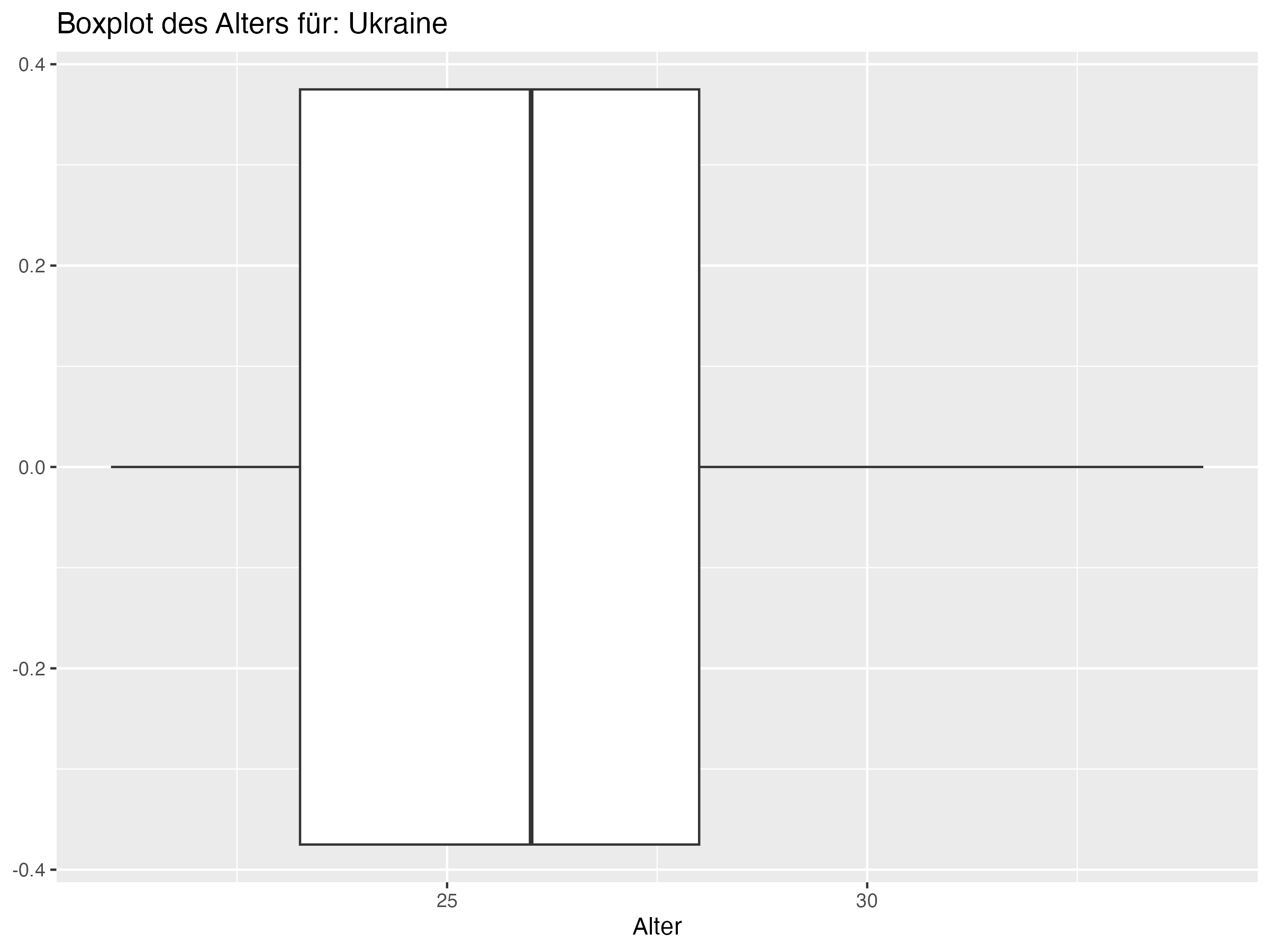
Cluster 1: England, Niederlande, Italien, Ukraine, Türkei, Österreich, Tschechien, Rumänien
Cluster 2: Frankreich, Portugal, Spanien, Belgien, Georgien, Slowakei
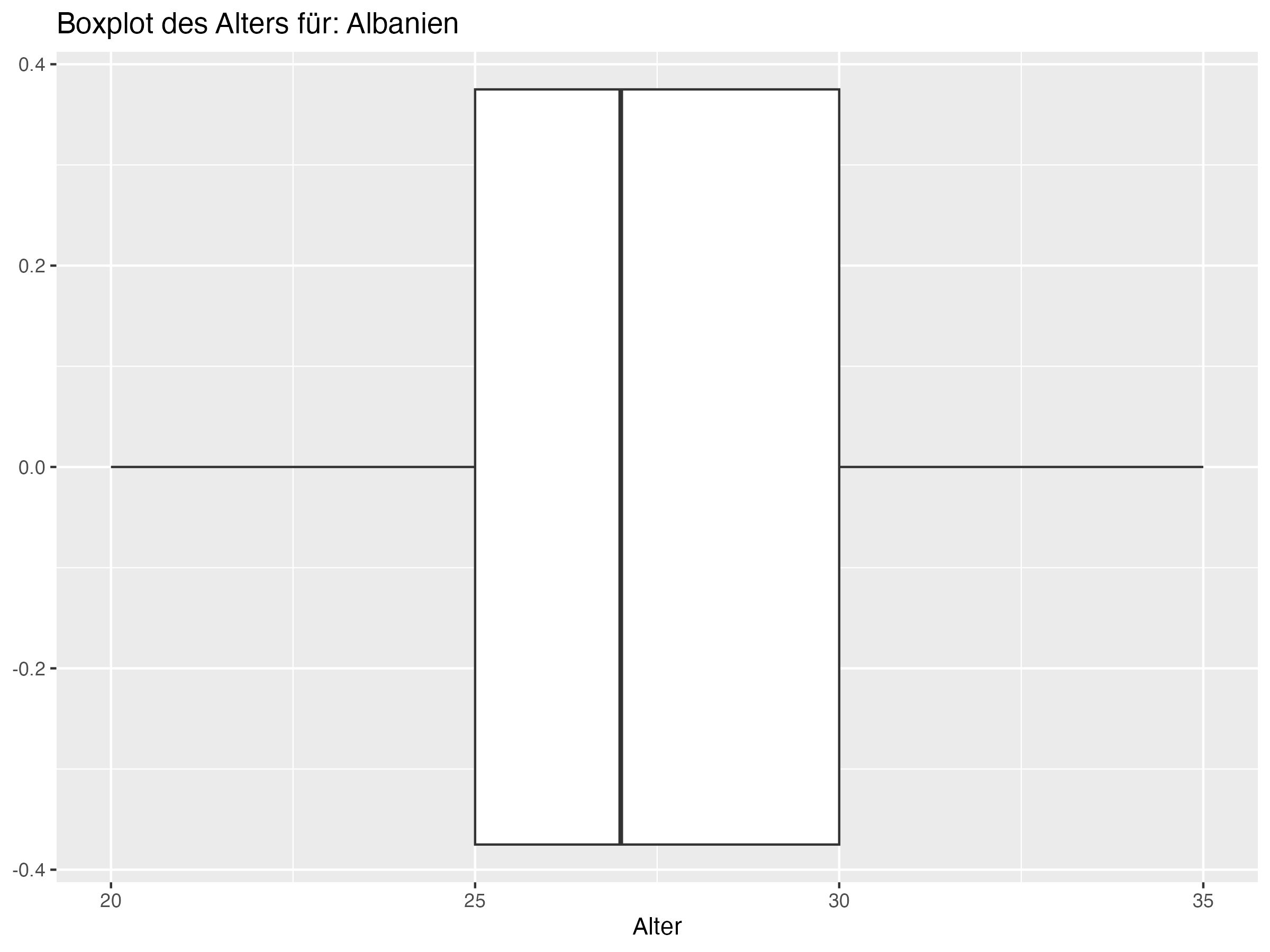
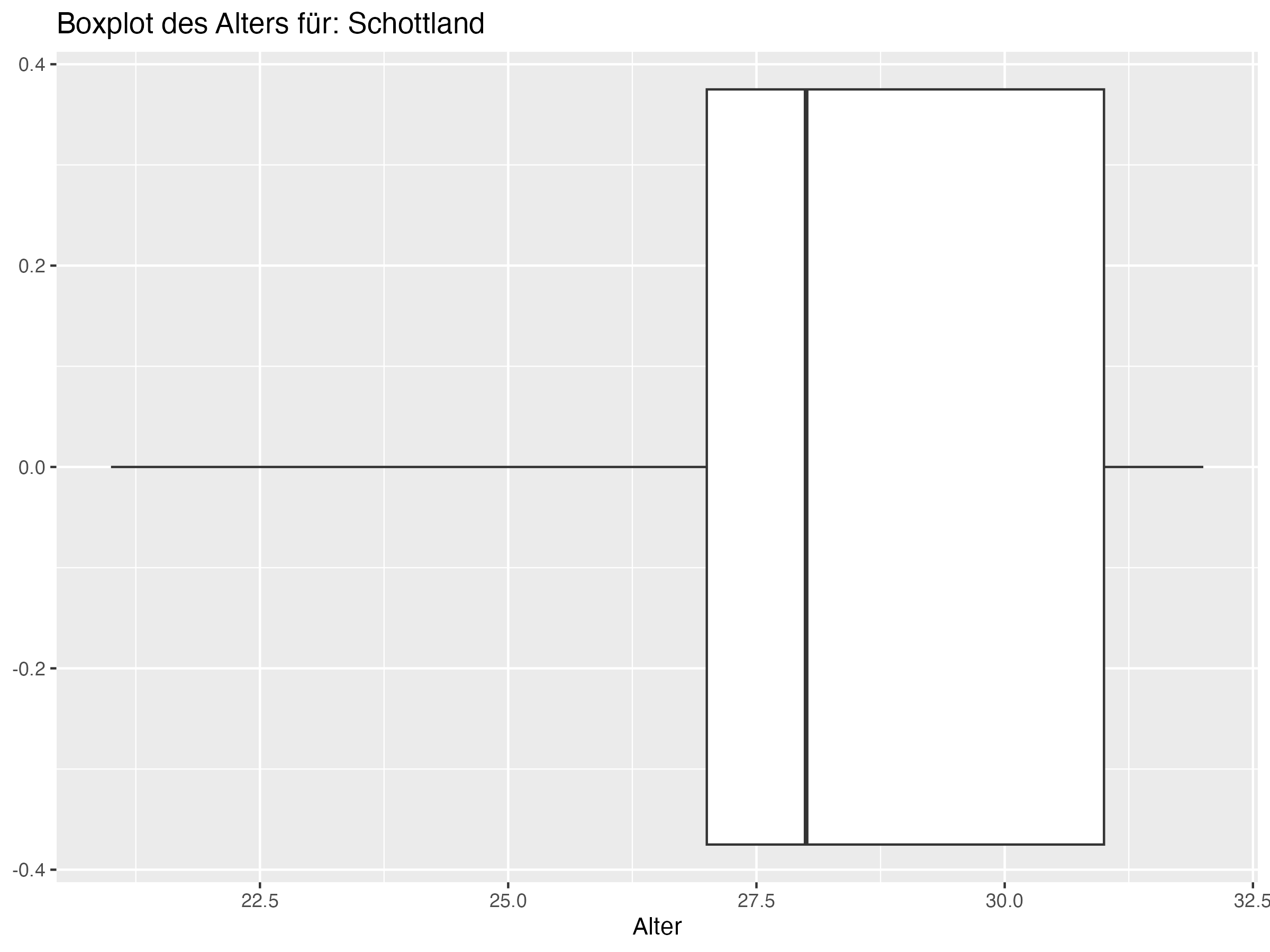
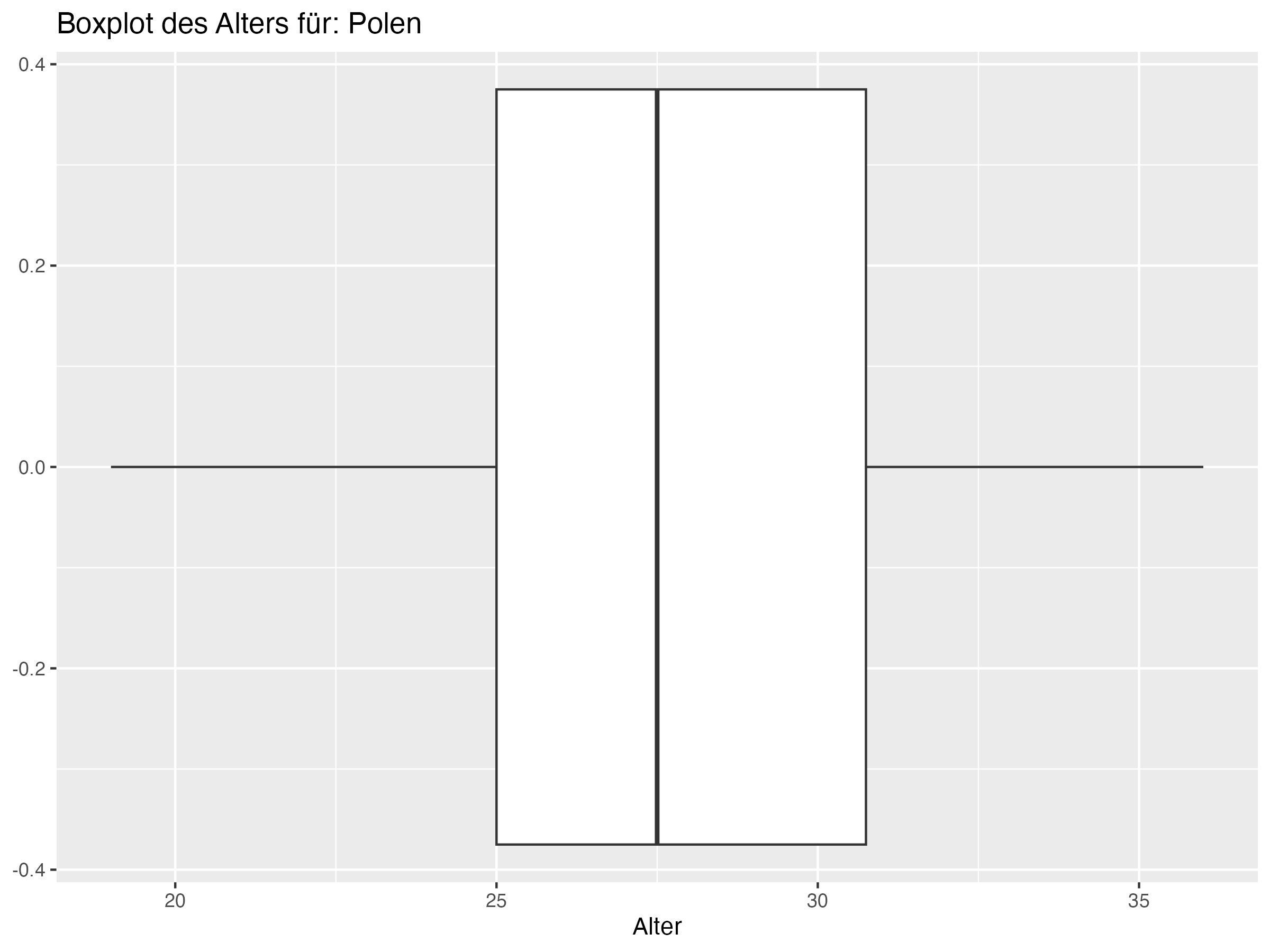
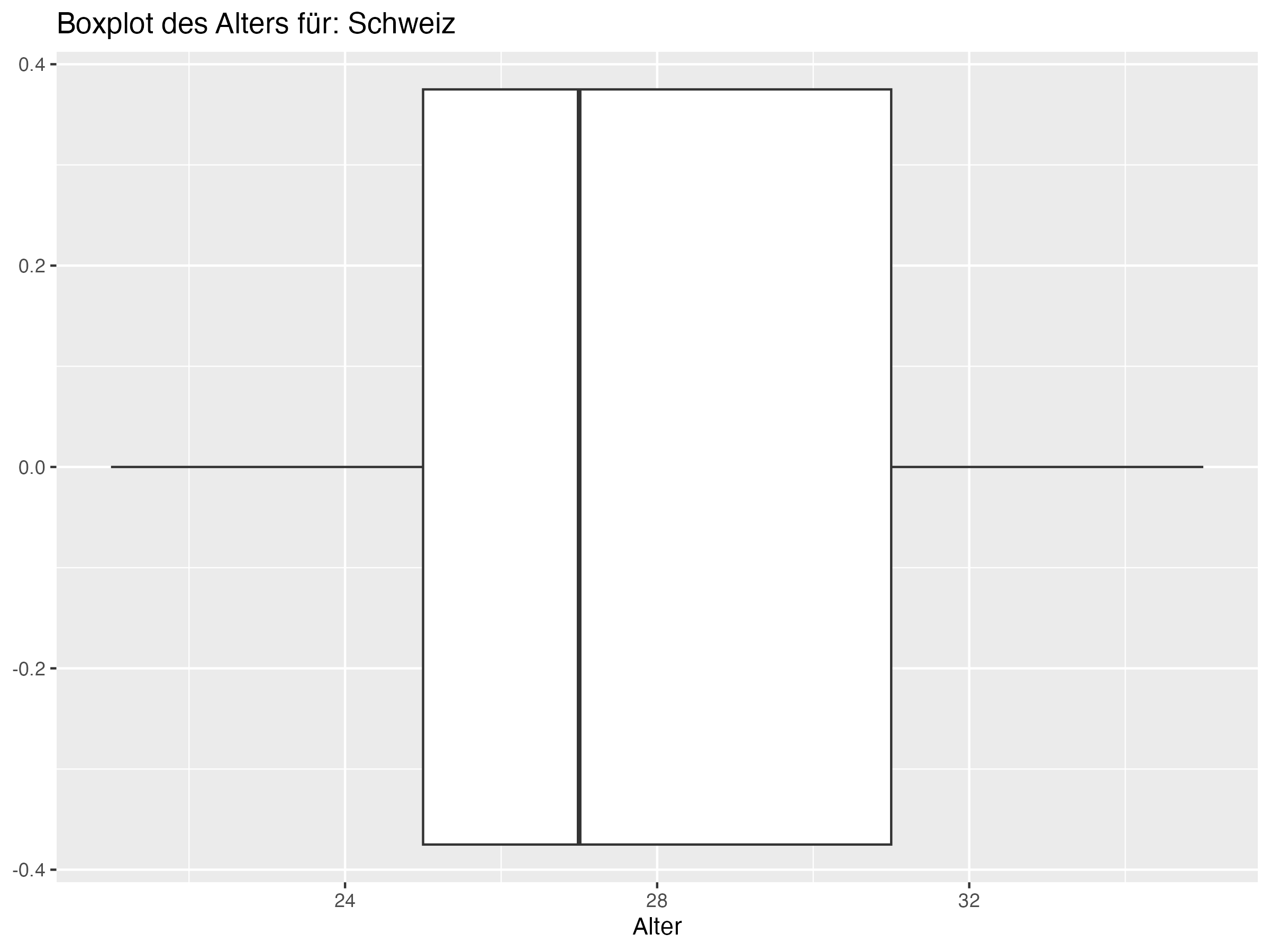
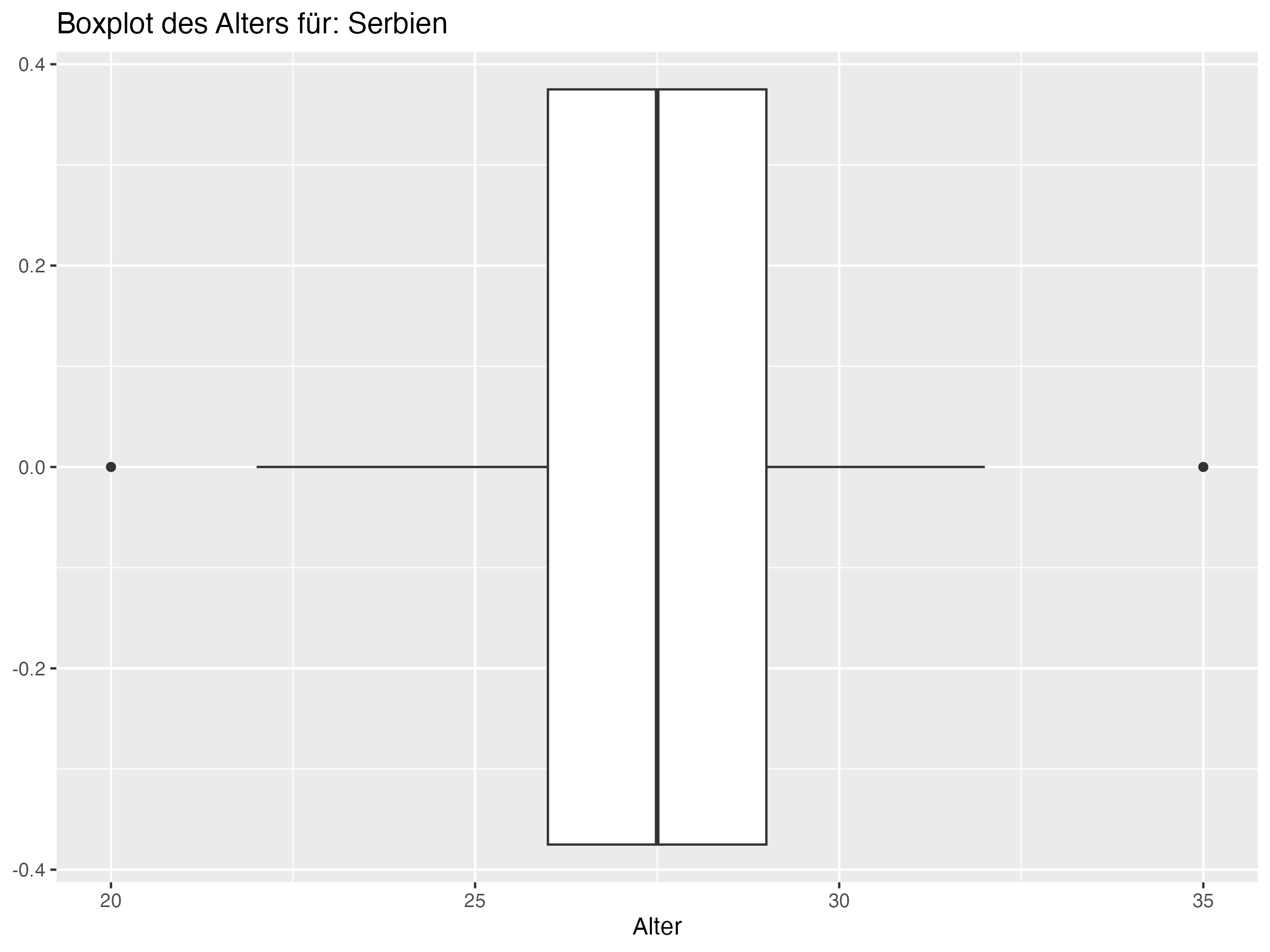
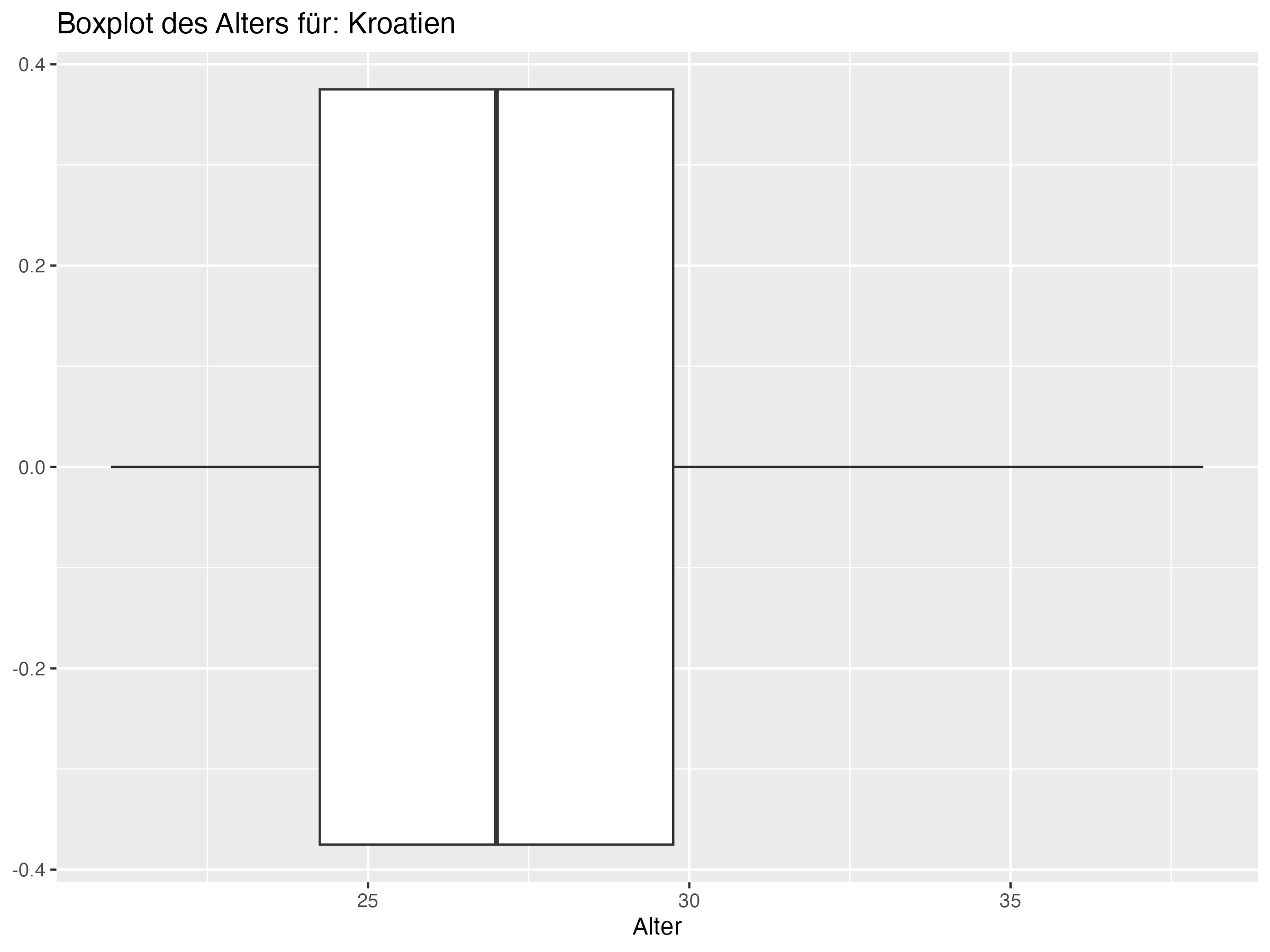
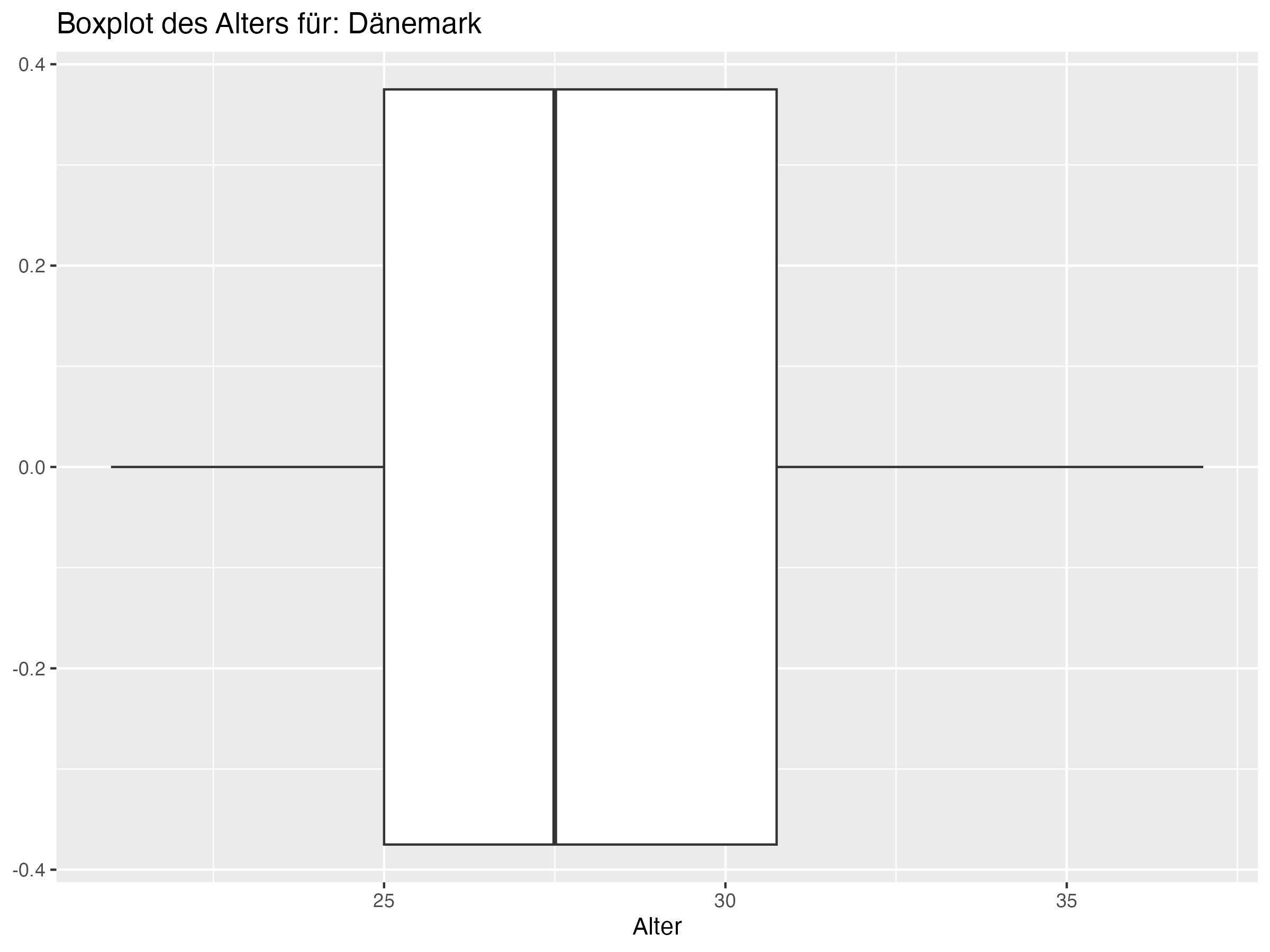
Cluster 3: Deutschland, Dänemark, Kroatien, Serbien, Schweiz, Polen, Schottland, Ungarn, Slowenien, Albanien
Interaktive HTML-Tabelle
Zusätzlich zur grafischen Visualisierung wurde eine interaktive HTML-Tabelle erstellt, die die Altersdaten der Teams sowie ihre Clusterzugehörigkeit anzeigt. Diese Tabelle ermöglicht eine einfache Sortierung und Filterung der Daten, was die Analyse weiter erleichtert. Die interaktive Tabelle ist im Anhang verfügbar und bietet detaillierte Einblicke in die Altersstrukturen der Teams.
4 Diskussion
Implikationen der Ergebnisse
Die Ergebnisse dieser Studie haben mehrere bedeutende Implikationen für die Teamzusammensetzung und die strategische Planung im Fußball. Durch die k-means Clusteranalyse wurden drei Hauptcluster identifiziert, die verschiedene Altersprofile der Teams widerspiegeln. Diese Erkenntnisse können Trainer und Manager bei der Gestaltung ihrer Teams und der langfristigen Planung unterstützen.
- Cluster 1: Teams in diesem Cluster, wie England, Niederlande und Italien, haben tendenziell jüngere Spieler und eine geringere Altersdiversität. Diese Teams könnten von der Einführung erfahrener Spieler profitieren, um strategische Tiefe und Stabilität hinzuzufügen. Erfahrene Spieler können als Mentoren für jüngere Talente dienen und in entscheidenden Momenten des Spiels für Ruhe und Übersicht sorgen. Ein ausgewogener Mix aus jungen, dynamischen Spielern und erfahrenen Führungspersönlichkeiten könnte die Leistung und Resilienz dieser Teams erhöhen.
- Cluster 2: Dieser Cluster umfasst Teams wie Frankreich, Portugal und Spanien, die eine hohe Altersdiversität und höhere Maximalalter aufweisen. Diese Teams sollten die Balance zwischen jungen und alten Spielern beibehalten, um ihre Vielseitigkeit zu maximieren. Eine solche Balance ermöglicht es den Teams, sowohl von der Energie und Anpassungsfähigkeit der jungen Spieler als auch von der Erfahrung und strategischen Weitsicht der älteren Spieler zu profitieren. Die Herausforderung für diese Teams besteht darin, die Integration von Nachwuchstalenten zu fördern, während sie gleichzeitig die wertvollen Beiträge der älteren Spieler nutzen.
- Cluster 3: Teams wie Deutschland, Dänemark und Kroatien, die tendenziell ältere Spieler haben, könnten von der Integration jüngerer Spieler profitieren, um die zukünftige Leistungsfähigkeit zu sichern. Eine kontinuierliche Erneuerung des Kaders durch junge Talente ist notwendig, um den altersbedingten Abgang erfahrener Spieler zu kompensieren und die Dynamik und Innovation im Team zu erhalten. Dies erfordert eine sorgfältige Nachwuchsförderung und die Schaffung von Gelegenheiten für junge Spieler, Erfahrungen auf höchstem Niveau zu sammeln.
Limitierungen der Studie
Diese Studie basiert auf Daten von 24 europäischen Nationalmannschaften und fokussiert sich ausschließlich auf Altersverteilungen, ohne die individuellen Leistungsdaten der Spieler oder die spezifischen taktischen Anforderungen der Teams zu berücksichtigen. Dies stellt eine wesentliche Einschränkung dar, da die Leistungsfähigkeit eines Teams nicht nur vom Alter, sondern auch von anderen Faktoren wie technischen Fähigkeiten, taktischem Verständnis und körperlicher Fitness abhängt. Zudem können kulturelle Unterschiede und spezifische Trainingsmethoden die Teamzusammensetzung und Leistungsfähigkeit beeinflussen.
Weiterhin wurde die Analyse ausschließlich auf Nationalmannschaften angewendet, wodurch Vereinsteams und deren dynamische Transferstrategien unberücksichtigt bleiben. Nationalmannschaften weisen eine relativ stabile Spielerstruktur auf, während Vereinsteams häufige Änderungen im Kader erleben, die ebenfalls analysiert werden könnten.
Zukünftige Forschung
Zukünftige Forschung sollte die Analyse der Altersverteilung mit individuellen Leistungsdaten und taktischen Aspekten kombinieren, um ein umfassenderes Bild der Teamdynamik zu erhalten. Es wäre wertvoll, zu untersuchen, wie Altersstrukturen mit spezifischen Leistungsmetriken wie Toren, Assists, Laufleistung und Passgenauigkeit korrelieren.
Eine weitere interessante Forschungsrichtung könnte die Untersuchung der langfristigen Leistungsentwicklung von Teams in Abhängigkeit von ihrer Altersstruktur sein. Hierbei könnten Längsschnittstudien durchgeführt werden, um den Einfluss von Altersänderungen im Team über mehrere Turniere hinweg zu analysieren.
Zudem wäre es aufschlussreich, die Altersverteilung in Vereinsmannschaften im Vergleich zu Nationalteams zu untersuchen. Vereinsmannschaften unterliegen anderen Dynamiken, wie regelmäßigen Transfers und Leihgeschäften, die ihre Altersstruktur und Teamdynamik erheblich beeinflussen können. Ein Vergleich könnte interessante Unterschiede und Gemeinsamkeiten aufzeigen und weitere Einblicke in die optimale Teamzusammensetzung bieten.
Schlussfolgerung
Schlussfolgerung: Diese Studie zeigt, dass die Altersverteilung ein wichtiger Faktor bei der Klassifizierung und Analyse von Fußballteams ist. Die k-means Clusteranalyse hat gezeigt, dass europäische Nationalmannschaften in drei Hauptcluster eingeteilt werden können, die verschiedene Altersprofile repräsentieren. Diese Erkenntnisse bieten wertvolle Informationen für die Kaderplanung und die strategische Ausrichtung von Teams. Durch die Integration dieser Erkenntnisse können Trainer und Manager fundierte Entscheidungen treffen, um die Leistungsfähigkeit ihrer Teams zu optimieren.
Die Identifikation der unterschiedlichen Altersprofile und deren Implikationen ermöglicht es, gezielte Strategien für die Teamzusammensetzung und -entwicklung zu entwickeln. Letztlich trägt dies zur Verbesserung der Gesamtleistung und Wettbewerbsfähigkeit der Teams bei.
Anhang
Takeaways
Basierend auf den durchgeführten Analysen und den daraus resultierenden Clusterzuordnungen können die folgenden Forschungsfragen beantwortet werden:
Hauptforschungsfrage:
- Wie variieren die Altersstrukturen der europäischen Nationalmannschaften bei der EM 2024?
- Die Altersstrukturen variieren signifikant und lassen sich in drei Hauptcluster einteilen: Cluster 1 (jüngere Spieler, geringere Altersdiversität), Cluster 2 (große Altersdiversität, höhere Maximalalter) und Cluster 3 (ältere Spieler, moderate Altersdiversität).
Nebenforschungsfragen:
- Inwiefern beeinflusst das Durchschnittsalter eines Teams seine Klassifizierung in verschiedene Cluster?
- Teams mit einem jüngeren Durchschnittsalter tendieren zu Cluster 1, während Teams mit höherem Durchschnittsalter oft in Cluster 3 zu finden sind. Cluster 2 enthält Teams mit einer breiten Altersspanne und hoher Diversität.
- Wie korrelieren die Altersverteilungen mit der Leistung und Strategie der Teams bei der EM 2024?
- Während diese Studie keine direkten Leistungsdaten einbezieht, legen die Altersverteilungen nahe, dass Teams in Cluster 1 möglicherweise mehr auf Jugend und Dynamik setzen, während Cluster 3-Teams auf Erfahrung bauen. Cluster 2 bietet eine Mischung aus beidem.
- Welche Teams zeichnen sich durch eine besonders hohe oder niedrige Altersdiversität aus?
- Teams in Cluster 2, wie Frankreich und Portugal, zeichnen sich durch eine besonders hohe Altersdiversität aus, während Teams in Cluster 1, wie England und die Niederlande, eine geringere Altersdiversität aufweisen.
Hinweise zum Datensatz
Die Daten wurden am 17. Juni 2024 erhoben und betreffen die Europameisterschaft 2024 in Deutschland. Der Datensatz umfasst 24 europäische Nationalmannschaften und enthält folgende Variablen:
- Land: Name des Landes.
- Minimum: Mindestalter der Spieler.
- 1. Quartil (Q1): Der erste Quartilwert des Alters.
- Median: Der Medianwert des Alters.
- Mean: Der Mittelwert des Alters.
- 3. Quartil (Q3): Der dritte Quartilwert des Alters.
- Maximum: Maximalalter der Spieler.
- SD: Standardabweichung des Alters.
- Range: Spannweite des Alters (Max - Min).
- Diff: Differenz zwischen dem Mittelwert und dem Median des Alters.
- Cluster: Zugehörigkeit des Landes zu einem der drei Cluster.
R Code
# Load necessary libraries
library(dplyr)
library(ggplot2)
library(cluster)
library(factoextra)
library(DT)
library(htmlwidgets)
# Daten laden
df <- data.frame(
Land = c("Tschechien", "Türkei", "England", "Niederlande", "Ukraine", "Italien", "Österreich", "Belgien", "Frankreich",
"Spanien", "Portugal", "Rumänien", "Georgien", "Slowakei", "Albanien", "Slowenien", "Serbien", "Ungarn",
"Kroatien", "Schweiz", "Dänemark", "Polen", "Schottland", "Deutschland"),
Minimum = c(20, 18, 19, 21, 21, 22, 20, 19, 18, 16, 19, 22, 18, 18, 20, 21, 20, 20, 21, 21, 21, 19, 21, 21),
Q1 = c(23, 23.25, 23.25, 23, 23.25, 25, 23.25, 23, 25, 24.25, 24, 25, 23, 23, 25, 25, 26, 23.25, 24.25, 25, 25, 25, 27, 26.25),
Median = c(25, 26, 26, 25, 26, 26, 26.5, 26, 26, 27, 26, 26, 27.5, 27.5, 27, 26, 27.5, 28.5, 27, 27, 27.5, 27.5, 28, 28),
Mean = c(25.5, 25.81, 26.08, 26.27, 26.35, 26.54, 26.81, 26.88, 26.92, 27, 27, 27, 27.15, 27.15, 27.31, 27.31, 27.38, 27.46, 27.69, 27.69, 27.73, 27.85, 28.31, 28.58),
Q3 = c(28, 28.75, 28, 29.75, 28, 27.75, 30, 31, 29, 29.75, 29.75, 28, 29.75, 29.75, 30, 30, 29, 31, 29.75, 31, 30.75, 30.75, 31, 31.75),
Max = c(31, 35, 34, 34, 34, 34, 35, 37, 37, 38, 41, 36, 38, 38, 35, 36, 35, 34, 38, 35, 37, 36, 32, 38),
SD = c(3.19, 4.22, 3.97, 4.03, 3.79, 2.87, 3.83, 4.95, 4.22, 4.76, 5.56, 3.35, 4.62, 4.62, 4.12, 4.04, 3.45, 4.37, 4.39, 3.86, 4.18, 4.26, 2.99, 4.36),
Range = c(11, 17, 15, 13, 13, 12, 15, 18, 19, 22, 22, 14, 20, 20, 15, 15, 15, 14, 17, 14, 16, 17, 11, 17),
Diff = c(0.5, -0.19, 0.08, 1.27, 0.35, 0.54, 0.31, 0.88, 0.92, 0, 1, 1, -0.35, -0.35, 0.31, 1.31, -0.12, -1.04, 0.69, 0.69, 0.23, 0.35, 0.31, 0.58)
)
# Entfernen der Land-Spalte für die Cluster-Analyse
df_cluster <- df %>% select(-Land)
# Standardisieren der Daten
df_scaled <- scale(df_cluster)
# Optimale Anzahl der Cluster bestimmen
fviz_nbclust(df_scaled, kmeans, method = "wss")
# K-means Clustering mit 3 Clustern (als Beispiel)
set.seed(123)
kmeans_result <- kmeans(df_scaled, centers = 3, nstart = 25)
# Cluster-Ergebnisse hinzufügen
df$Cluster <- as.factor(kmeans_result$cluster)
# Visualisierung der Cluster mit Länderlabels
fviz_cluster(kmeans_result, data = df_scaled, geom = "point", ellipse.type = "convex",
ggtheme = theme_minimal(), main = "K-means Clustering der Teams",
label = df$Land)
# Anzeige der Ergebnisse
print(df)
# Ausgabe der Cluster-Zentren
print(kmeans_result$centers)
# Anzeigen, welches Land zu welchem Cluster gehört
cluster_info <- df %>% select(Land, Cluster)
# Erstellen einer sortierbaren HTML-Tabelle mit Cluster-Zugehörigkeit
datatable(df %>% mutate(across(where(is.numeric), ~ round(.x, 2))),
options = list(pageLength = nrow(df),
autoWidth = TRUE,
dom = 'Bfrtip',
buttons = c('csv', 'excel', 'pdf', 'print')),
rownames = FALSE,
colnames = c("Land", "Minimum", "1. Quartil", "Median", "Arithmetisches Mittel", "3. Quartil", "Maximum", "Standardabweichung", "Spannweite", "Diff. Mittel-Median", "Cluster")) %>%
formatStyle(columns = 1:ncol(df), fontFamily = 'Open Sans') %>%
saveWidget(file = "Zusammenfassung_Alter_Laender.html")


Bitte beachten sie auch unseren Disclaimer:

